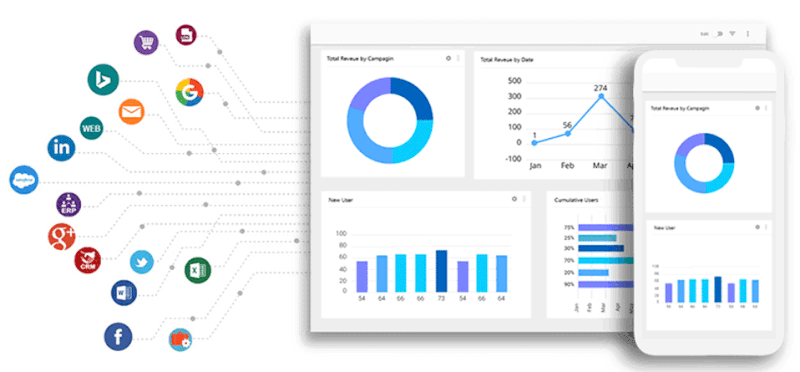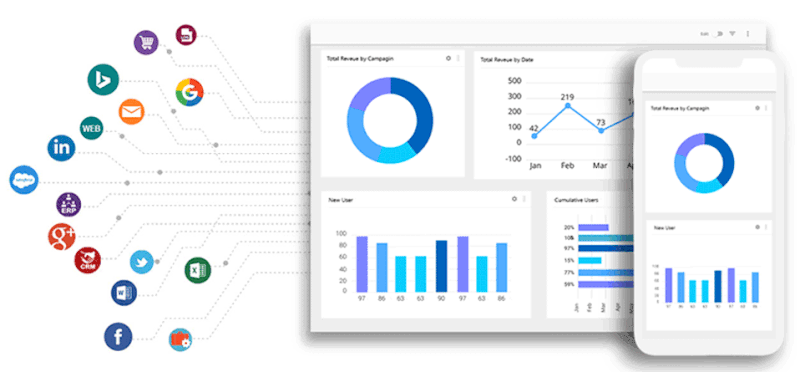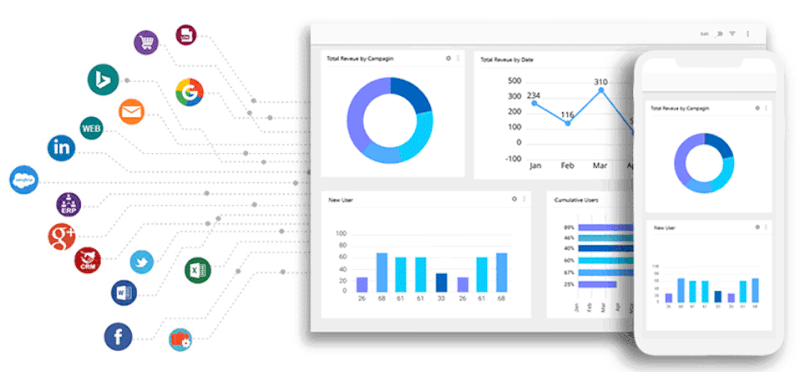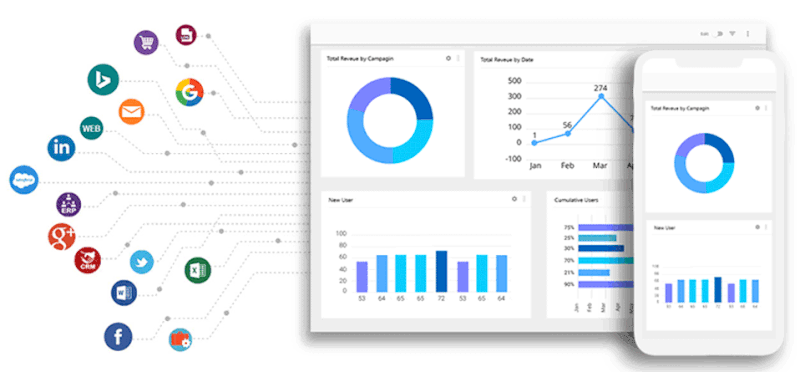

I’ve joined projects where the “data warehouse” was just a folder of CSV exports: CRM, web analytics, email campaigns, partners, ad platforms — each with its own format and fields. At first, it feels like progress: data is collected, spreadsheets are full. But the moment you try to connect the dots across sources, everything breaks.
Why is this a problem?
Without unification and automation, the data never becomes a single customer story. Instead you get:
• Duplicates that inflate your numbers.
• Gaps where data should align but doesn’t.
• Time mismatches that make revenue appear on the wrong day.
The result? A business that stops trusting analytics. I’ve seen execs dismiss entire dashboards because two CSVs didn’t line up — not because the strategy was wrong, but because the files simply weren’t consistent.
Analytics is only as strong as its foundations. Twenty disconnected CSVs aren’t a foundation — they’re a liability. Real stability comes only when sources are normalized and collected automatically. Otherwise, you’re not analyzing data, you’re just juggling chaos.
So how do you fix it?
When I step into these projects, the playbook is clear:
• Build a unified ETL/ELT pipeline with schema normalization.
• Align on identifiers and time zones.
• Use a single storage layer as the source of truth.
• Document the process so the system survives beyond one person.
Good analytics doesn’t come from more CSVs. It comes from fewer, reliable pipelines.
Want all my best GA4-BQ queries in one place? I turned them into a Chrome extension — top SQL queries you can search and copy in seconds.
Go here to install it for FREE.
Prefer the web version? It's here.