
Why does COUNT(DISTINCT) feel like the safe choice?
Exact is better than approximate. That's the default assumption. When I need unique user counts, I use COUNT(DISTINCT) - it's precise, it's familiar, and I trust it.
Where does it become a problem?
COUNT(DISTINCT) on large GA4 datasets is resource-intensive. It requires holding all distinct values in memory before deduplicating. On a year of data across millions of users, it's slow and expensive — especially running daily across multiple dimensions.
For monitoring dashboards, weekly trend reports, and exploratory analysis, burning that compute for exact precision is often overkill.
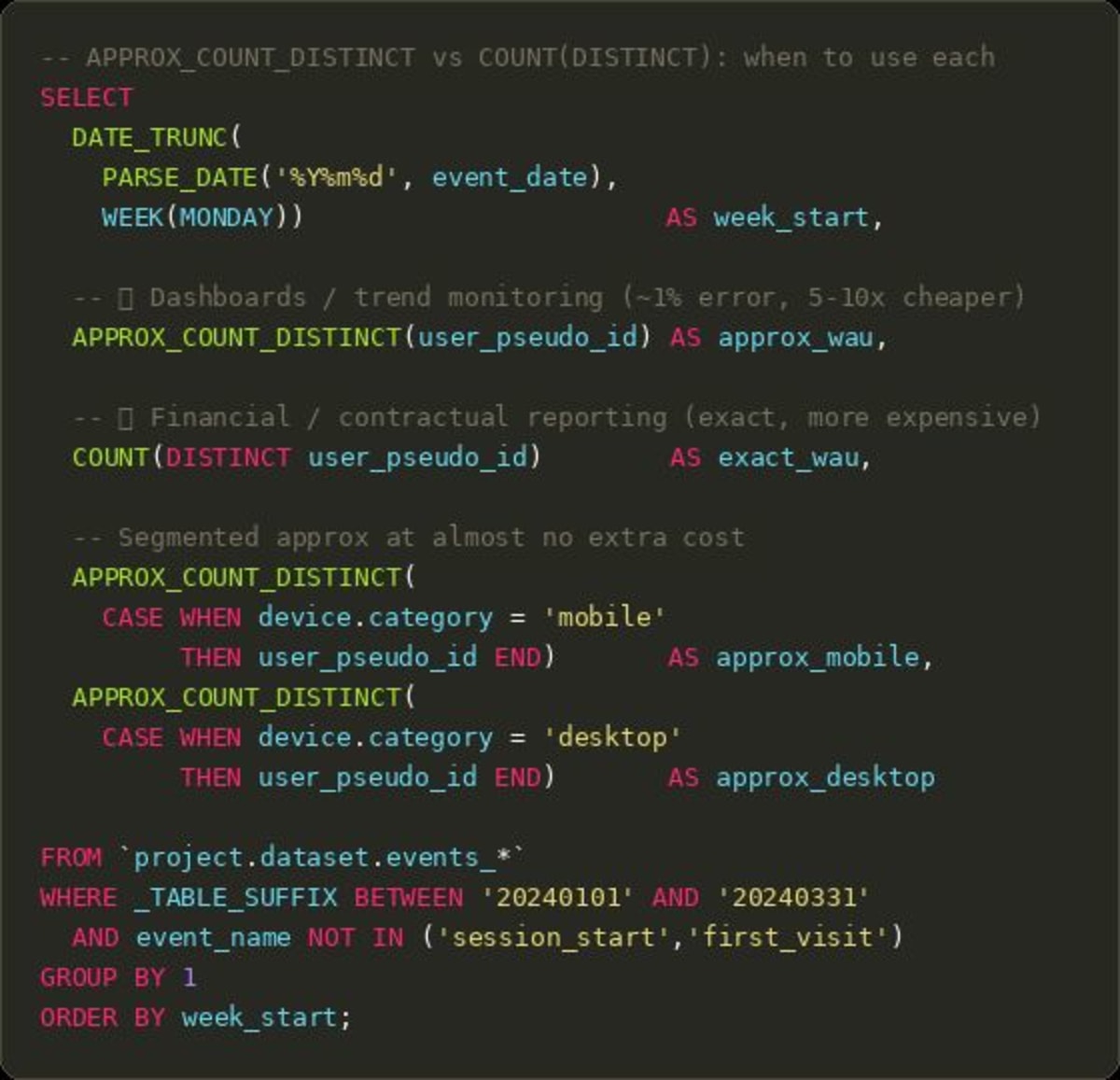
What does APPROX_COUNT_DISTINCT offer?
It uses the HyperLogLog++ algorithm. Error rate is around 1% — a true count of 1,000,000 users might come back as 990,000 or 1,010,000. For spotting trends, alerting on anomalies, or reporting week-over-week changes, that error is invisible. The performance difference can be 5-10x faster and proportionally cheaper.
When should you use which?
Clear rules I follow:
- Financial reporting, billing, or contractual metrics: COUNT(DISTINCT), always exact
- Operational dashboards, trend monitoring, ad-hoc exploration: APPROX_COUNT_DISTINCT
Knowing when precision matters and when it doesn't is the difference between a well-run analytics function and one that burns budget on exactness no one asked for.
Want to get all my top Linkedin content? I regularly upload it to one Notion doc.
Go here to download it for FREE

