
Why does A/B analysis feel done when the query runs?
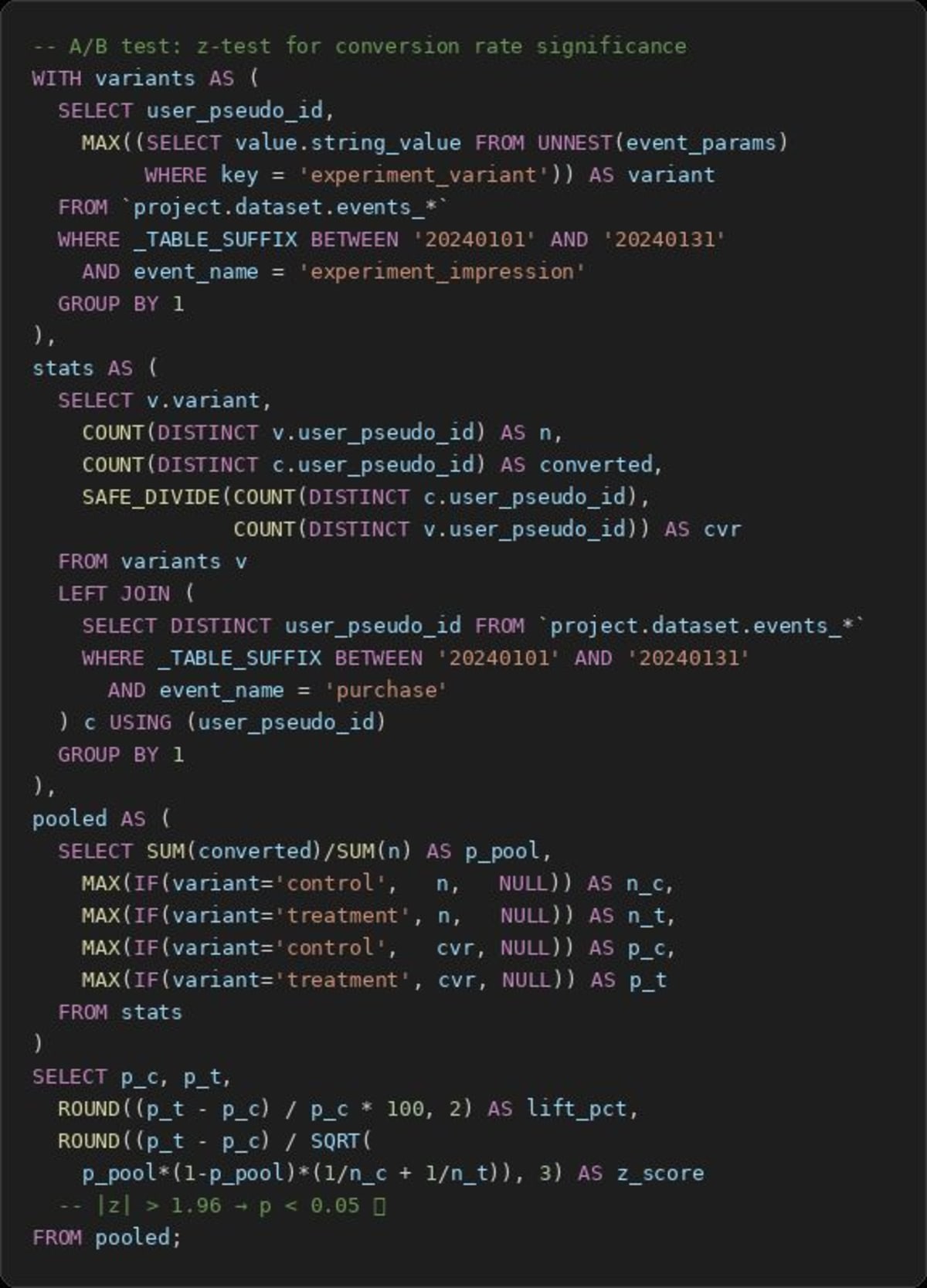
You split traffic, collect events in GA4, pull both variants into BigQuery, calculate conversion rates. Variant B shows 2.8% vs Variant A's 2.4%. You ship Variant B. Simple.
What's actually missing?
Statistical significance. Two percentages are not a conclusion — they're an observation. With small samples, the difference you're seeing could easily be random noise. Most A/B analyses I've reviewed had:
- Sample sizes too small to detect real effects
- Test periods too short
- No check for novelty bias or seasonal overlap
Shipping the wrong variant because of random fluctuation is an expensive mistake. I've seen it happen more than once.
What does a proper test look like in BigQuery?
Run a z-test for proportions:
- Count conversions and total users per variant
- Calculate the pooled proportion
- Compute the z-score and derive the p-value
- Or calculate a confidence interval directly
All of this is doable in SQL. It's not glamorous, but it turns two numbers into an actual decision.
Why does this matter beyond the test itself?
Every feature shipped based on a flawed test degrades product quality silently. A/B tests without statistics aren't experiments — they're coin flips with extra steps. Getting this right once sets the standard for every test after it.
Want to get all my top Linkedin content? I regularly upload it to one Notion doc.
Go here to download it for FREE

